Technology
Development
Code
Como Construir um Identificador de Sentimentos em Python
17 de jun. de 2020

Nesse post iremos adentrar em como é possível conseguirmos com poucos passos realizar uma analise de sentimento de um determinado texto, utilizando Machine Learning para atingir este resultado desejado. O objetivo é compreender os passos iniciais para lidar com a manipulação de textos e em como aplicá-los em um algoritmo de ML.

Importância de Machine Learning Atualmente e o que Iremos Construir
Hoje vivemos em um contexto em que compreender e aplicar conhecimentos de ML se tornam cada vez mais importantes no mercado. Com isso, adquirir conhecimentos mesmo que realizando projetos simples, pode ter uma grande diferença na carreira de qualquer pessoa. Com esse intuito, iremos abordar alguns conceitos iniciais de uma área de IA que é o processamento de linguagem natural ( Natural Language processing: NLP ).
NLP é um campo de pesquisa na área de Ciência da Computação e Inteligência Artificial cujo objetivo é o processamento de linguagem natural, como Português ou Inglês, em dados que tenham algum sentido para o computador. Infelizmente, os computadores não conseguem compreender frases simples que estamos acostumados no nosso dia-a-dia, por isso é necessário ter algum tipo de "tradução" para que eles possam realizar algum tipo de operação com esses dados. O campo de NLP é vasto, podendo abranger a criação e aprimoramento de chatbots, analise de sentimentos, reconhecimento de fala e reconhecimento de escrita.
Nesse post iremos criar um simples modelo que irá identificar se um pedaço de texto contém sentimentos positivos ou negativos. Primeiro passo para isso são os dados, precisamos de dados para treinar nosso algoritmo. Iremos usar uma base de dados do IMDB com reviews de filmes para construir nosso modelo, você poderá baixar esses dados através deste link.
Nesse tutorial iremos usar o Jupyter Notebook para desenvolvermos nossa aplicação. Iremos utilizar o notebook por meio da plataforma Anaconda, que você poderá acessar clicando neste link. Não entrarei muito em detalhes sobre o processo de instalação, já que este não é o propósito deste post. Porém, caso tenha alguma dificuldade, basta seguir esses tutoriais caso você utilize Mac, Windows ou Linux.
Qual Algoritmo e Método Usar?

Se você já está familiarizado na área de ML, já sabe que podemos seguir alguns passos para a criação de qualquer modelo. Podemos utilizar algoritmos de regressão linear ou algoritmos de redes neurais, podemos também treiná-los de forma supervisionados ou não supervisionados. Apenas para dar um introdução nesses temas, irei explicar brevemente caso alguém que esteja lendo não tenha conhecimento sobre esses temas.
Algoritmos de machine learning como objetivo receberem um valor de entrada, o input, e gerar um valor de saída, output, valor esse que poderá conter algum significado para o usuário utilizando esses algoritmos. Quando se trata de algoritmos de regressão linear eles possuem níveis de processamento menor que algoritmos de rendes neurais. Ou seja, quando temos um input para algoritmos de regressão linear, o valor de entrada será processado por uma camada e produzirá um valor de saída. Porém, quando se usa redes neurais como opção, o dado de entrada será processado por várias camadas, com isso, sua modificação ao longo do caminho será maior do que algoritmos de regressão linear. Aqui fiz uma explicação mais simplificada de como ambas as abordagens funcionam, mas já é possível ter uma ideia da diferença entre as duas opções de algoritmos. Nesse post não iremos utilizar um algoritmo de redes neurais, iremos numa abordagem mais simples utilizando um algoritmo de LogisticRegression para a construção de nosso modelo.
Outro ponto citado seria a diferença entre utilizar um aprendizado supervisionado e não supervisionado para treinar nosso algoritmo. Ambos os casos você precisa utilizar dados para que o algoritmo aprenda, mas aprendizado supervisionado terá a indicação de qual será a resposta correta. Ou seja, supondo que estamos realizando um treinamento de um algoritmo para identificar imagens de cachorros. Para treinar nosso modelo, nós precisamos fornecer fotos de cachorros, fotos de outros animais e indicar por uma label qual é qual, assim nós estamos utilizando um aprendizado supervisionado, onde indicamos qual a resposta final desejada. O método não supervisionado tem uma finalidade diferente, pois não há uma resposta final certa, ou seja, seu propósito muda com o problema que você queria solucionar.
De voltar ao projeto, ao baixar os dados do IMDB, você poderá abrir o arquivo baixado e verá a seguinte estrutura de pastas, contendo essas duas que serão as mais importantes para esse projeto que são as de Test e Train. A pasta de Train será usada para treinarmos nosso algoritmo e a de Test para validarmos a acurácia do nosso modelo. Ao abrir a pasta de Train, você verá os seguintes arquivos:
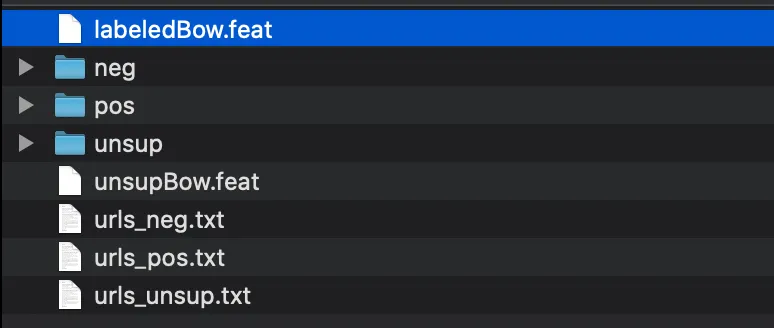
Não se preocupe com nenhum dos arquivos do tipo txt ou feat, eles não serão importantes aqui. Devemos nos atentar as três pastas neg, pos, unsup. Como foi explicado, iremos utilizar um aprendizado supervisionado e estamos mostrando para o nosso algoritmo quais reviews são positivas, negativas ou neutras ( unsup ). Porém, não iremos precisar da pasta unsup, ela pode ser deletada caso você queria.
Como falado anteriormente, iremos utilizar o algoritmo de Logistic Regression na construção do nosso projeto. A escolha deste algoritmo se encaixa na proposta que queremos desenvolver, pois este algoritmo é bastante usado para classificação entre decisões binárias, por exemplo, determinar se um e-mail é spam ou não. Como o algoritmo funciona, também está fora do escopo deste post, mas caso tenha curiosidade você pode acessar este link para entender mais.
Bibliotecas
Antes de começarmos, gostaria de apresentar algumas bibliotecas que são utilizadas ao longo do projeto direta ou indiretamente.
Scikit-learn é um biblioteca open source que contém vários algoritmos de ML para usarmos. Caso o leitor queira se aventurar e contribuir, o link para o repositório é este.
NumPy é um pacote do python que contém funcionalidades para lidar com arrays multidimensional, ou outras funções matemáticas um poucos mais complexas. Importante avisar que o scikit-learn receber variáveis do tipo NumPy em seus algoritmos, por isso é interessante saber da existência deste pacote.
Pandas é um biblioteca para analise de dados, com ela podemos utilizar uma função DataFrame para conseguirmos visualizar nossos gráficos facilmente.
Mãos à Obra
Para iniciar basta inicializar Jupyter Notebook e criar um novo arquivo:
Após isso, iremos carregar nossos dados de treino realizando os seguintes comandos:

Aqui estamos utilizando a biblioteca sklearn e sua função load_files para conseguirmos carregar os dados de treinamento. Após isso, iremos extrair os dados que realmente importam para nós, que no caso seria o data e o target da variável reviews_train.
Pronto, caso você esteja interessado em ver como estão os dados que iremos utilizar, basta utilizar a função print do Python para conseguir visualizar o resultado.
Precisamos também carregar nossos dados de teste, utilizando a mesma lógica feita anteriormente:
Agora que temos nossos dados precisamos realizar mais alguns passos. Como expliquei anteriormente, nosso algoritmo de classificação é muito bom para classificações binárias, ou seja, quando esperamos resultados de sim ou não. Mas como lidar com texto ? Precisamos realizar algumas manipulações com esse texto para que ele faça sentido para o computador.
Bag of Words
Uma das soluções mais simples, porém mais efetivas e usadas é a utilização do algoritmo bag of words. Este algoritmo descarta quase toda a estrutura do texto, parágrafos, sentenças, etc. O objetivo dessa abordagem é conseguir quebrar a estrutura macro de um texto para assim conseguirmos uma estrutura menor, que seria as palavras e com isso dar prosseguimento na manipulação destes dados. A entidade mais importante é a palavra e quantas vezes ela é utilizada ao total. Esse algoritmo tem um passo a passo para poder ser concluído, por sorte no python já existe uma função que irá realizar esse processo por nós.
1. Primeiro passo, devemos utilizar a Tokenização. Essa ação irá dividir texto que é a nossa entidade macro, para uma entidade menor que será a palavra. Como mostra nessa imagem:
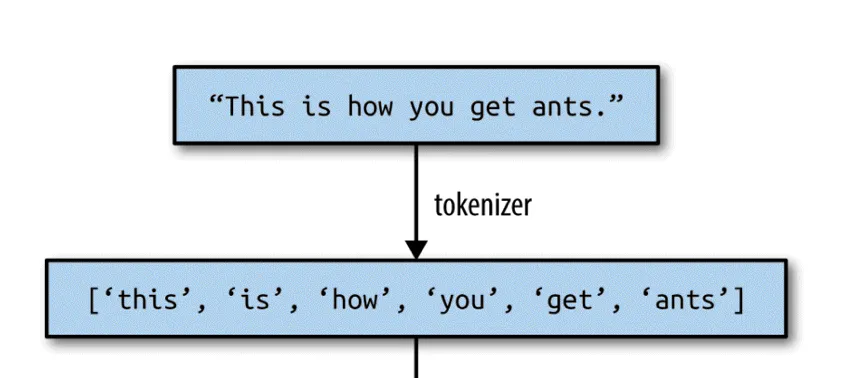
Ou seja, Tokenização é apenas quebrarmos a estrutura de um determinado texto em palavras, para que assim possamos contar sua utilização em todos os textos subsequentes.
2. Segundo passo é coletar todas as palavras usadas em todos os textos. Ou seja, juntar todos os tokens gerados pelos diversos arquivos de dados.
3. Terceiro passo é contar quantas vezes cada palavra aparece ao longo dos dados coletados. Portanto, no final teríamos um vector representando a seguinte estrutura:
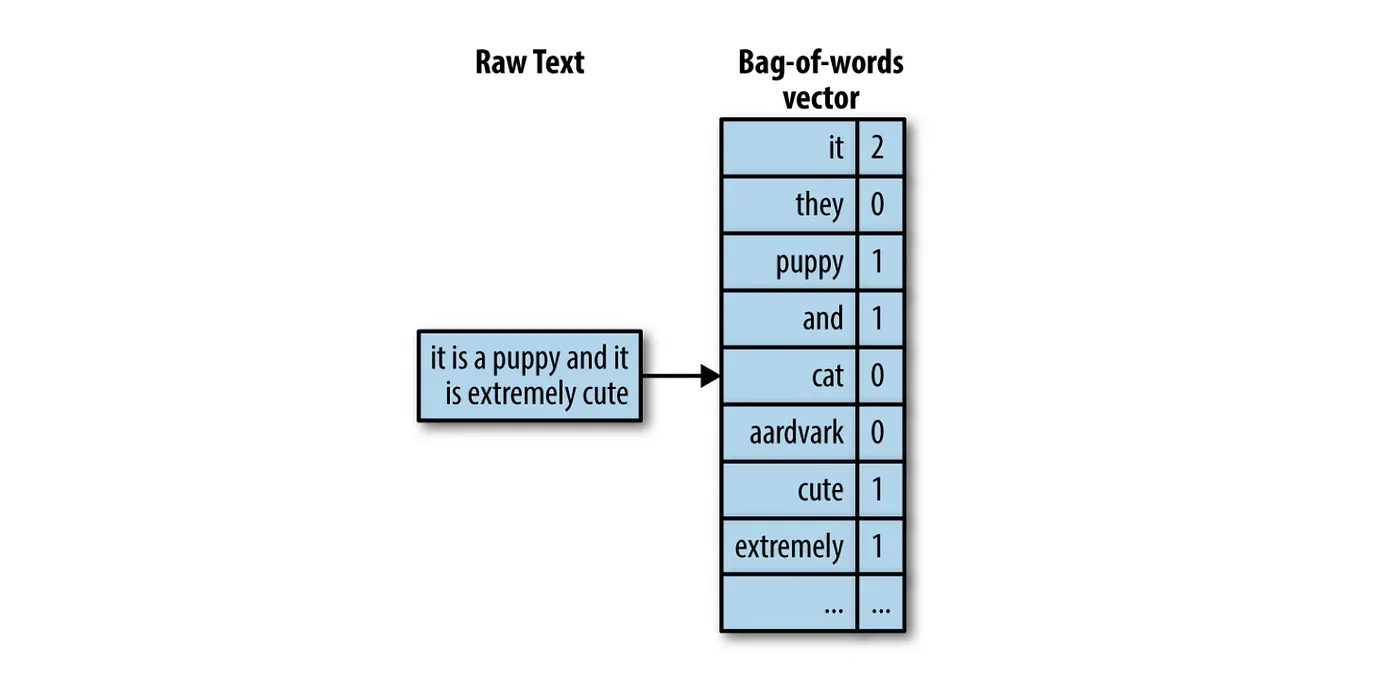
Iremos utilizar novamente uma função do sklearn chamanda CountVectorizer. Está função irá executar o pipeline descrito acima para que não precisemos fazê-lo todo a mão, nos poupando tempo.

Essa linha de código contém duas funções, a fit que é responsável por extrair nossos parâmetros, ou seja as palavras presentes no texto. A outra função a transform é responsável por contabilizar em um vector quantas vezes cada palavra está sendo usada ao longo dos nossos dados de treino.
Uma vez com nossos dados devidamente extraídos, podemos aplicar o algoritmo de Logistic Regression:

Nesta parte estamos realizando duas operações. A primeira, estamos importando a função LogisticRegression e a cross_val_score do sklearn para assim podermos treinar nosso modelo. Em seguida estaremos verificando qual o melhor valor para esse atributo C, que será explicado mais a frente. Daremos algumas opções para esse atributo e aplicando outra função do sklearn conseguimos identificar que o melhor valor será 0.1. Assim nosso modelo terá um score conforme mostra a imagem abaixo:

Nosso primeiro output é o atributo cross-validation score que indica a precisão da função gerada pelo logistic regression. Ou seja, essa atributo indica uma precisão de quase 90% ao indicar se uma review foi positiva ou negativa.
Agora você tem um algoritmo pronto para identificar se uma review de um filme é positiva ou negativa.
O Que é Esse Parâmetro C?
Ao treinar qualquer modelo de ML podemos ter diversas variáveis em nossos dados. Por exemplo, vamos supor que temos um dataset com informações de preços de casas, essas informações podem conter várias colunas que se referem ao ano da compra, ao bairro, etc. Ou seja, o problema é identificar quais dessa informações são relevantes para nosso modelo. Por de baixo dos panos é aqui que esse parâmetro C irá atuar.
Ao definir esse parâmetro estamos buscando regularizar nossos dados para que não tenhamos dados enviesados. Ou seja, se escolhermos um número grande de informações como relevantes, nosso modelo será bom apenas para identificar dados que correspondam as entradas dos dados de teste. Ou seja, caso nosso input não tenha alguma informação, sua acurácia alta não será confiável. Porém, caso optemos por usar um número baixo de informações, nosso modelo também será muito específico de determinadas entradas, podendo não levar em consideração outras igualmente relevantes.
Por isso realizamos esse passo de escolher qual o melhor valor para C, assim nosso algoritmo terá um grau de confiabilidade maior.
Próximos Passos
Está foi um pequeno projeto feito para aprofundar um pouco mais no mundo de ML. Nosso objetivo ao longo do ano é nos aprofundarmos cada vez mais nesse assunto. Continuaremos focados em aprender mais sobre NLP, aplicando em algumas soluções, como por exemplo: como podemos levar isso para construção de chatbots ? Como podemos usar redes neurais para melhorar nosso algoritmos ? São passos que iremos aprender e compartilhar.
